Any strictly proper score decomposes into uncertainty − resolution + reliability (Bröcker, 2009, generalizing the Murphy decomposition of the Brier score to any proper score).
The decomposition
For a forecast γ and target Y, write:
s(p,q)=∑kS(p,k)qk — expected score of forecast p when Y∼q
e(p)=s(p,p) — generalized entropy
d(p,q)=s(p,q)−e(q) — divergence
πγ=P(Y∣γ) — recalibrated forecast
πˉ=E[πγ] — climatology (the marginal of Y)
Then Bröcker’s Eq. (13), for any strictly proper loss S, is
E[S(γ,Y)]=e(πˉ)−E[d(πˉ,πγ)]+E[d(γ,πγ)].
It is the Savage split s(γ,πγ)=e(πγ)+d(γ,πγ), then E[e(πγ)]=e(πˉ)−E[d(πˉ,πγ)] by linearity of s(πˉ,⋅).
Cross-entropy
The log score sets s(p,q)=H(q,p), e(p)=H(p), d(p,q)=KL(q∥p), giving
E[−logγY]=H(Y)−I(Y;γ)+E[KL(πγ∥γ)].
Uncertainty — the base-rate entropy H(Y)
Resolution — the mutual information I(Y;γ) between output and target
Reliability — the calibration gap E[KL(πγ∥γ)], zero iff γ=πγ
A constant forecast scores H(Y); an oracle maximizes I(Y;γ) and zeroes the gap.
How it’s estimated
Resolution and reliability both need πγ, which we don’t have in closed form. We estimate it by bucketing: γ is the model’s predicted distribution, Y‘s marginal is the dataset disease base rate, and πγ is each γ-bucket’s empirical gold rate. The decomposition is therefore an estimate (bucket-dependent), but the ordering of methods holds across choices.
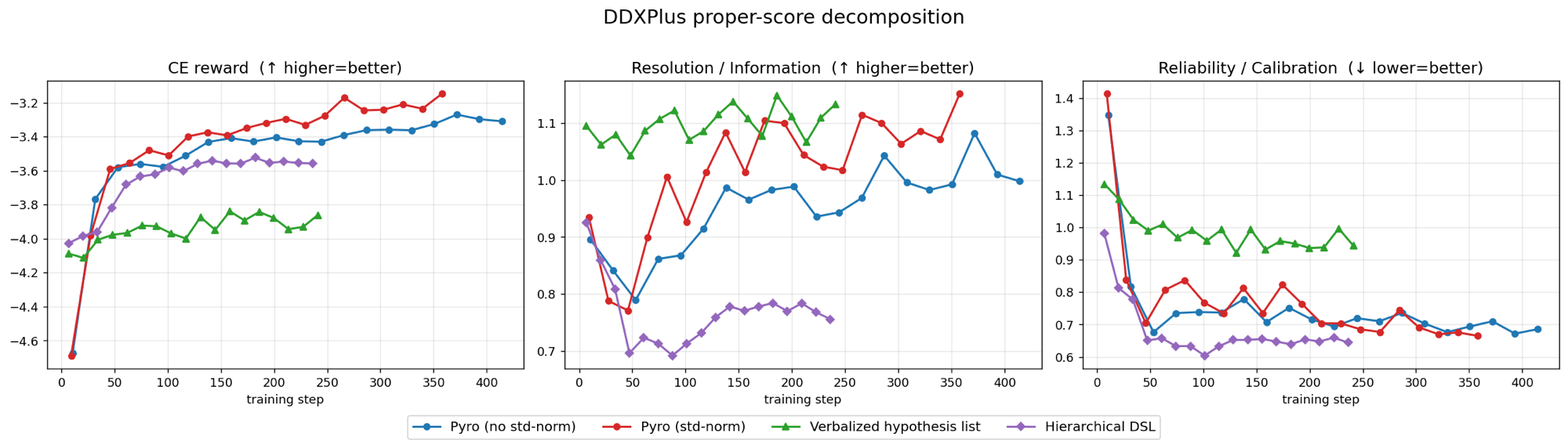
On DDXPlus
The decomposition across four output representations — Pyro ±std-normalization, the verbalized hypothesis list, and the hierarchical DSL. Pyro with std-normalization (red) reaches higher reward and resolution than without (blue) while reliability tracks it — no overconfidence on this distributional target, the opposite of the MedMCQA replication. Mechanism: σ-normalization.